How We Handle LLM Drift: A Ten-Phase Task Lifecycle
The task lifecycle we run at Imagineers to capture chain of thought and beat session compaction on long-running agent tasks.
Krishnanand B
April 10, 2026
For a long time we thought about LLMs the same way we thought about any other tool. The point was the output. The PR that merged, the test that passed, the feature that shipped. The LLM was a faster way to get there.
Then, across long-running tasks, the same thing started showing up. Drift. Small decisions contradict earlier ones. Plans lose the reasoning that produced them. Tests pass for reasons nobody asked for. Each PR looks fine in isolation. The cost lands months later, when someone comes back to the code and cannot explain why it looks the way it does.
A 2% per-turn misalignment does not stay at 2%. Over a long task, it compounds into roughly a 40% failure rate.
That is when the frame shifted. If the work is turning a ten-day feature into a one-day feature, the expertise is not in the feature. It is in whatever is compressing the ten days into the one: the conventions, the checks, the order in which we ask questions, the things we always re-read before writing code. All of that is the harness. The output is a side effect.
Invest in the harness, not the output. The output takes care of itself.
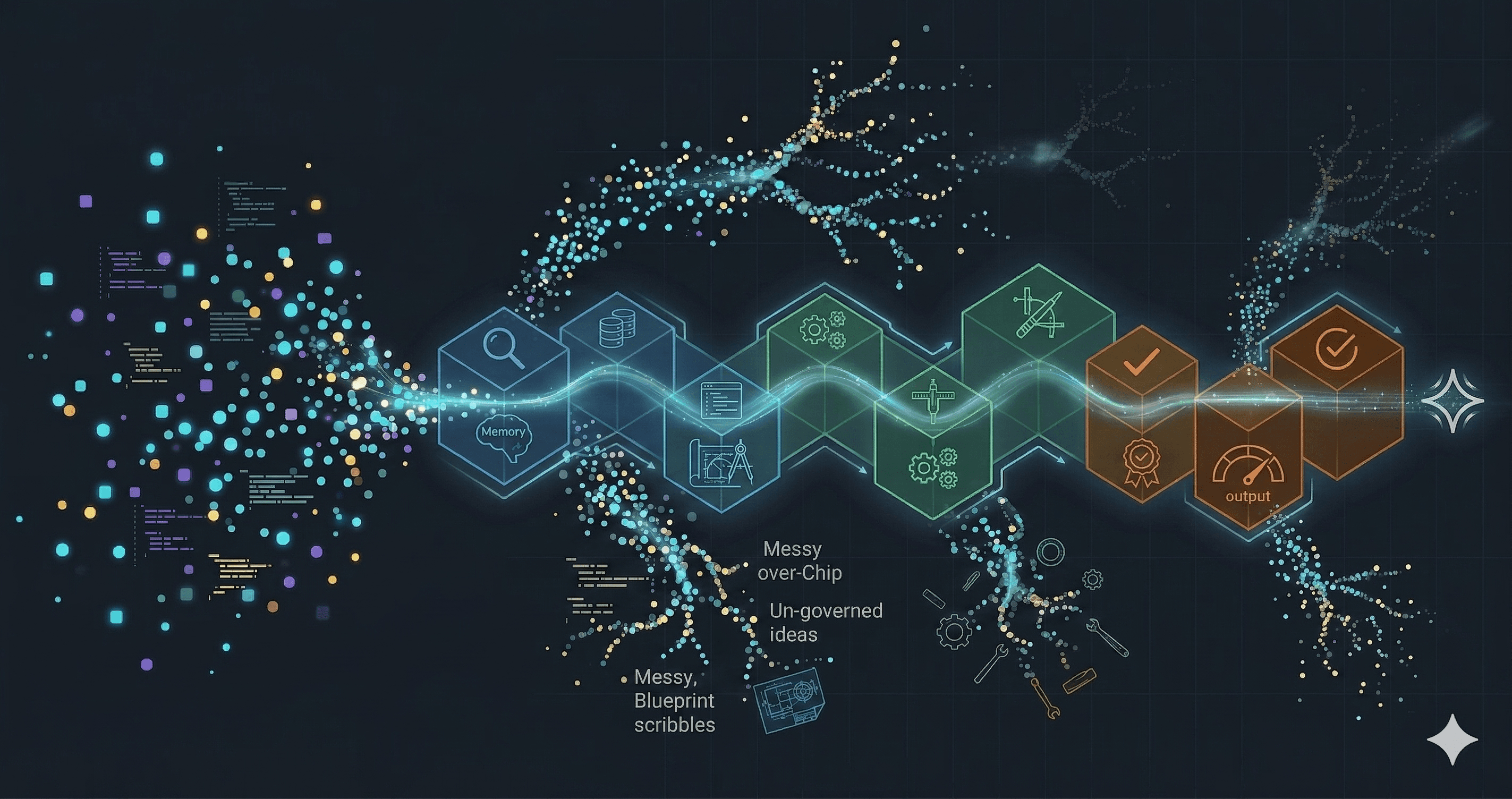
A note on scope. We focus on one slice of harness engineering: how to maintain context, run the feedback loop, and control drift during execution.
How memory systems fit, and where they leave a gap
The first place we looked was memory. We use memory systems; they are a real part of the stack. But when we traced where drift was hiding, it kept showing up in the same three places.
- Memory systems compact by design. A memory is a summary of what was decided, not a full transcript of how the decision was reached. That is the right shape for a memory. It is also the shape drift hides inside: a slightly-off summary is still a summary, and slightly-off is how drift starts.
- Sessions compact too. Every agentic tool compresses its context as the session grows. Compaction is distillation. The system keeps the decisions and sheds the detail. On a week-long feature across three contexts, the things that get distilled away are the things you need later: the alternatives ruled out, the constraint that shaped the choice, the unknown that never got resolved.
- The input was written for a human. A ticket describes an outcome at a level of detail that assumes a human engineer will assemble the rest through kickoffs, informal pings, and quiet midday chats with the person who last touched this file. That assembly is the real specification. An agent has no access to any of it. Tools like Linear are building AI-native workflows that chip away at the gap. In our experience, a story written for humans is still a different artifact from a specification written for an LLM.
All three point in the same direction. Information that lives somewhere (in a memory summary, in a prior session's compacted context, in a colleague's head) has to end up in a file the agent can read in full. Files preserve the chain of thought. Files do not compact. Files do not go home at five. Everything after this point is the discipline of getting the information into the files and keeping it there.
The shape of one task
The lifecycle runs against one task at a time. A large story decomposes into smaller tasks first, each small enough to hold in one reasoning session. Ten phases sounds like a lot. In practice the phases group into four arcs, and each arc exists to answer one question honestly before the next one starts.
Are we solving the right problem?
The first three phases make sure the human and the agent agree on what is being asked, in writing, before any plan exists.
- Understand. Read-only loading. The agent pulls the task definition, the relevant conventions, the adjacent code, and any closed tasks in the same module. Nothing is written yet.
- Capture. The agent puts its own interpretation into a file, in plain language, with four sections: the goal, what is in scope, what is out of scope, and what it does not yet know.
- Align. The human reads the captured interpretation and confirms or corrects it. This is the first human gate. A drifting reading of the task gets caught here, before it becomes a wrong plan.
For a task that adds missing E2E coverage to a checkout page, the file Capture writes looks something like this:
# .context/tasks/checkout/promo-coverage.md
---
status: captured
---
## Goal
Add end-to-end Playwright coverage for the promo code feature on
the checkout page. Three scenarios: a valid code applies the
discount, an invalid code shows an error, an expired code is
rejected.
## In scope
- Extend the CheckoutPage Page Object with promo helpers
- Add three fixtures, one per scenario
- Three E2E tests, one per scenario
## Out of scope
- Unit tests for the promo service
- Changes to the promo API itself
- Copy for the error message
## Unknowns
- What is the exact error text shown for an invalid code?
- Is there a known latency on the promo endpoint to wait for?
That last section is the one to watch. On any non-trivial task, an empty Unknowns list usually means the agent has not thought hard enough, not that there was nothing to ask. On a small, well-scoped task where you have already checked that the agent has the context it needs, an empty list is fine. The judgement is yours, not the template's.
A misread at the start propagates. Every downstream decision rests on what was captured here, so catching a wrong interpretation now is cheap. Catching it in Verify is not.
Are we taking the right approach?
The next three phases map the problem space and commit to a direction, still on paper.
- Explore. The agent maps the surrounding code: how similar problems have been solved, what patterns already exist, what options are on the table. It is the work a senior engineer does in their head before writing a plan, written down instead of held in memory.
- Plan. The agent commits to a direction and names what is in scope, what is out, and why.
- Design. When the task needs it, the plan gets translated into something concrete enough that the builder can implement it without making architectural decisions of its own. Not every task warrants a design document. The orchestrator asks, and we say yes only when the answer is clearly yes.
A minimal plan and design for the same checkout task, side by side:
This is the second human gate, and the last one before any code exists. Then the thinking commit closes the arc. Task, plan, and design go into git as one bracket, before any production code. If the direction turns out to be wrong three days later, the fix is to edit the files and rerun from Build. Nothing is thrown away. The git log reads as decisions first, code second, which is the order a reader three months from now will want to follow.
Is the code honest?
The third arc is the one that actually touches the codebase.
- Build. The agent implements what the design describes. It reads the design, not the whole codebase. Staying narrow is the point.
- Test. Handled by a separate sub-agent whose context holds only the design, never the implementation. A test-writer who has seen the implementation mirrors its blind spots. A test-writer who has seen only the design writes the tests the design implied and the builder forgot.
- Review. A self-audit against the plan before the code reaches a human.
- Verify. Runs the full suite, walks every acceptance criterion from the task file, and confirms each one with evidence.
Every code touch in this arc follows the same rhythm: write the test, run it red, make the change, run it green. A passing test before the code exists tests nothing meaningful. A red test that turns green without a reason is a fluke. The rhythm is not a habit. It is the mechanism that keeps the tests from becoming theater.
What does the next session read?
- Close. The agent writes a short summary into the task file and propagates what it learned: a new pattern into the memory layer, a new decision into the decision log, a session entry that names what was done and what comes next. The deliverable commit closes the bracket. Implementation, review notes, and close notes all go into git.
The two commits together read as the full record: what we decided, what we built, and what the next person should know.
Close is the asymmetry. Every other phase takes from the memory layer. Close is the only phase that gives back. A lifecycle without a real Close degrades into rediscovery, every task starting from the same zero the last one did.
Drift will still happen
After all of this, we have to be brutally honest. Drift will still happen. Ten phases does not make it go away. On a long enough task, some interpretation will slip, some constraint will be misread, some assumption will go unchecked. There is no way to engineer that out.
What the harness actually buys is not immunity from drift. It is a trail of artifacts dense enough that when drift does show up, we can find it. A later session reads the task file, the plan, the design, and the close notes, and if they no longer line up, the agent can trace the discrepancy back to the specific decision that caused it and reconcile from there. Without the trail, drift is invisible. With it, drift becomes a bug with a stack trace.
That, to us, is the soul of this. Not drift-free engineering. Drift you can point at.
The substrate: where the loop closes
Everything the lifecycle does starts and ends here. A task opens by reading the substrate (the project's voice, its past decisions, the patterns it has already figured out), runs through the codebase across the ten phases, and closes by writing back to the same substrate. The loop begins and ends in these files. The ten phases are how we trace the chain of thought between the two ends.
For the substrate itself, we use the common knowledge-organization methods (PARA, Zettelkasten, Diátaxis) as a starting point, and borrowed one idea from each.
- PARA (Tiago Forte, from Building a Second Brain). A knowledge-organization method that files information by how actionable it is, not by topic. Projects, areas of ongoing responsibility, reference resources, and archives each live in separate folders so the most actionable material is always the easiest to reach. We took the actionability axis: the standards a project maintains and the notes it is still figuring out belong in different places.
- Zettelkasten (Niklas Luhmann, via Nick Milo). A note-taking method built on three rules: one idea per note, links between notes matter more than folder hierarchies, and a single central index serves as the entry point to everything else. We took the central index: one top-level file that an agent reads first, and uses to navigate to the rest.
- Diátaxis (Daniele Procida). A documentation framework that splits writing into four purposes: tutorials, how-to guides, reference, and explanation. The claim is that these serve different readers in different moods, so mixing them in one place makes everything harder to find. We use the four-way split as an output prompt: when the agent works on a new feature or concept, we ask it to produce all four — tutorial, how-to, reference, explanation. Writing through each in turn forces the agent to see the whole spectrum of the thing, not just the slice it found first.
Put together, this is how we structure the directory every task reads at Understand and writes to at Close.
.context/
├── identity/
│ └── SOUL.md ← project voice, non-negotiables
├── memory/
│ ├── MEMORY.md ← index
│ ├── DECISIONS.md ← append-only design decisions
│ ├── CONTEXT.md ← append-only patterns and conventions
│ └── SESSIONS.md ← append-only session log
├── orchestration/
│ └── how-to-*.md ← one guide per phase
├── standards/
│ └── checklist.md ← the quality bar, in one list
├── tasks/{category}/{slug}.md
├── plans/{slug}.md
└── designs/{slug}.md ← when warranted
Three things about this layer carry the weight.
SOUL.mdholds the project's voice in one file. When a session opens against a different project, we load itsSOUL.mdinstead and the agent inherits the point of view without reconstruction.- The
memory/layer is append-only, and the three logs are deliberately separate. A decision is a choice (why A over B). A pattern is a convention (how to use A correctly). A session is a narrative of what moved. They live in different files because they answer different questions for the reader. - Output styles pin a domain persona for the whole session. We stop telling the agent read the test style guide, read the fixture conventions. The style is the style guide.
This is where the loop closes. Every task reads the substrate at Understand and writes back at Close, a little thicker than it found it. The next task starts from a state that already knows more than the last one did.
What we have learned
Three things we keep coming back to.
-
A story written for a human is not a prompt for an LLM. Humans fill the gaps through kickoffs, informal pings, and conversations with the person who last touched the file. An LLM reads what is in front of it and proceeds. It needs fine-grained control of everything: goal, scope, constraints, unknowns, acceptance. Teams that put that work in up front get much better output. Teams that jump straight into development, assuming Claude will work it out, are testing the waters, and the drift only grows.
-
Even with all this in place, the LLM will still find a way to drift. Something small sneaks in every session. You have to be conscious of every step the agent takes to know it is still on track. The common belief is that working with LLMs gets easier over time. It does not. It is tiresome and attention-intensive. It needs dedicated focus, strict process guidelines, and a quick fallback for when things slide.
-
Every team will build its own version of this. Yours will not look like ours. The shape depends on your codebase, your risk profile, your definition of done, and what your team naturally pays attention to. The only real test of whether your harness is working is whether you can change a piece of the codebase months later without creating a regression. If that is easy, the harness is doing its job.
What the harness means to us
It comes down to two things.
-
The shape of the harness matters less than the fact that you have one. We are not claiming ten phases is the right answer, for anyone or even for ourselves. Yours will look different, and ours is still changing. What we are certain of is this: if you are building a harness that keeps a strict check on the LLM, you are already doing a far better job of controlling drift than if you are not.
-
Time collapses when the substrate is there. Every session opens against the same set of files, reads the same decisions, inherits the same voice. Nothing has to be re-explained. No context has to be rebuilt from what the last session already knew. The sessions stop feeling like sessions. They feel like one continuous conversation the agent never left. That, more than anything, is what a harness is for.
Enjoyed this article?
Get in touch to discuss how AI-powered testing can transform your QA processes.